Nov 23, 2023
AI Assistants Know Your Preferences, Even Better Than You Do

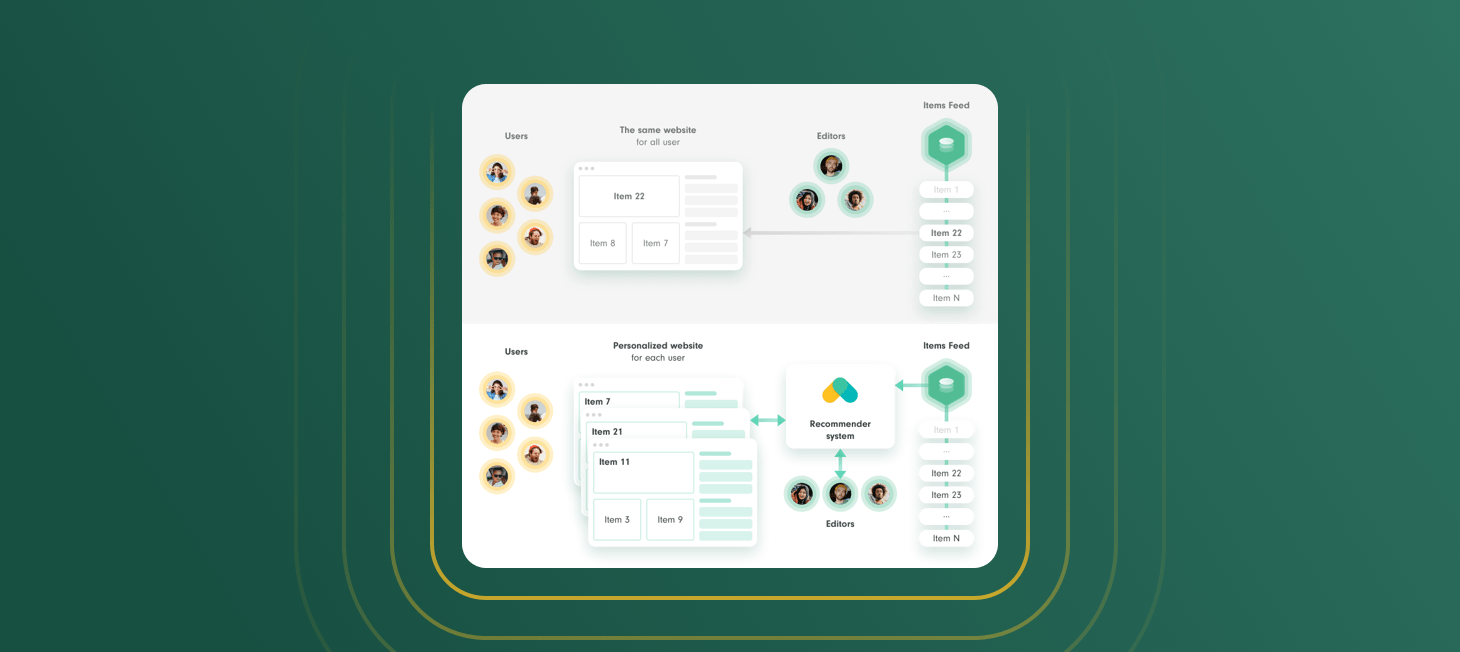
The internet and online services have changed significantly in the last decade. They are smarter. They can better understand what you might like. And that's thanks to the inconspicuous algorithms - recommender systems. These are currently the most widely used group of algorithms in practice, along with conversational intelligence. It is good to know about them and be aware of how they work.
Before the advent of the internet, scientists were working on how to help people navigate a large catalog of items. Information retrieval algorithms solved how to select the right documents from many documents, such as items in a public library, for visitors.
The original algorithms were based on the visitor entering what they were looking for, and the system returned the documents that best matched the query. These algorithms were not personalized. Everyone got the same results for the same query. Classic algorithms did not use machine learning and only solved the similarity of the query and the documents. The similarity of the query and the document was determined, for example, as the cosine distance of long sparse vectors counting the words that occur in these texts. In the vectors, in addition to the frequency of words, their importance was also taken into account. For example, the tf-idf method gives less weight to words that occur in most documents.
With the advent of the internet and online services, the size of various catalogs of items has exploded. In addition, it turned out that visitors often do not know what they are looking for. They would rather have something recommended to them, if the recommendation is relevant for them, which can be a real problem given the number of options. And here is where intelligent assistants in the form of recommender systems come in.
Users connect to online services through personal computers and mobile phones, which merchants can uniquely identify using so-called cookies. They are also often logged in to the service using their personal account. Thanks to this, their visits are not anonymous and service providers can track their behavior. The most interesting are, of course, various interactions with the items in the catalog, whether their viewing, purchase, or explicit evaluation (e.g., adding to favorite items).
Recommender systems enable online services to be personalized for individual users. Each user gets a different website containing items that were predicted relevant by AI algorithms powering the recommender system.
One of the first recommender systems was GroupLens, which started development in 1992 and recommended relevant articles to users based on their explicit historical interactions. However, it turned out that users are not very willing to rate items explicitly (stars, thumbs up or down), and therefore their preferences must be inferred from so-called implicit interactions (displaying an item, reading it, purchasing, etc.).
Modern recommender systems learn on the implicit interactions of visitors with items to offer what to whom when. And that in all possible areas. You can recommend songs, books, videos, goods, real estate, jobs, news, etc. Although different areas have their own specifics, recommender algorithms are very similar. And while information retrieval algorithms solved how to help the user find an item as quickly and accurately as possible, the goal of modern recommender systems is to help users discover relevant items that they may not know about yet and generally improve personalization and the associated user experience when using online services. This leads to the fact that users are more loyal, return to the service more often and for a longer period of time, and thus their value for the service provider increases overall.
The most common method used for this is called collaborative filtering, where we look for visitors with similar behavior and recommend items that the visitor has not yet seen. These algorithms help people discover new things on the given platform. The opposite are algorithms that remind visitors of items that they have already interacted with. Even that in itself is not a simple task, and algorithms must take into account the visitor's historical behavior as well as the periodicity of the items (how often visitors typically return to the item). Another class of algorithms are popularity algorithms (for example, contextual bandits), which recommend items trending in a group of users. Bandit algorithms try to balance appropriately between exploration and exploitation. Exploration offers users items that could become popular for that particular group. Exploitation then maximizes the use of already proven items that have been shown to work well for users. The system is rewarded, for example, if it recommends an item that the user is satisfied with. It gradually improves so that it maximizes the collected rewards (see reinforcement learning). Most modern algorithms also use the available information about the items (such as metadata such as text description, categories, images, etc.). These metadata are processed by modern neural networks and thus form their representation of the catalog of items. Thanks to this, they are able to recognize similar items, even if they are brand new and do not have any interactions yet. These algorithms are then often combined in a suitable way to create the final recommendation for the user. Algorithms must also be very fast (the user will not wait) and adaptive to various changes (for example, changes in the catalog of items).
Modern recommender systems are also able to help users even if they have a more specific idea of what they are looking for. The user then communicates this idea to the system through various interactions (text search, filtering, etc.). This has somewhat unified recommender algorithms with personalized search and ranking algorithms, which were historically separate research fields (also known as learning to rank).
Currently, there is a public debate on how to ensure that visitors to online services have control over what the systems recommend to them and what data they use for this. The right to privacy (I don't want to share any data or interactions about myself) is in conflict with the usability of the service (I want the recommender system to have as much information about me as possible and be able to offer me the most relevant items from the catalog immediately).
In my opinion, the user should be able to work with their user profile, similar to how we already know it from web browsers, where we can, for example, switch between multiple user profiles. Unfortunately, it is not yet entirely clear how to enable users to work effectively with their profile and how to represent their profile in a way that is understandable. Smaller online service providers may be the ones who suffer the most from any regulation, as the development of a user interface for configuring user profiles will be expensive. However, without the ability to use modern recommender algorithms, their online services and products will not be competitive, as all larger online services already use recommender systems, and personalization is to a certain extent already standard for users.
This text was originally written for the Czech edition of Wired journal in collaboration with prg.ai.
Next Articles

AI News and Outlook for 2024
We look at the most interesting research directions and assess the state of knowledge in key areas of AI. We'll also estimate future developments in 2024 so you know what to prepare for.
Jan 16, 2024

The AI (R)Evolution in the Media Industry
In today's digital age, personalization has become the cornerstone of the media industry. Whether it's tailoring content recommendations, refining marketing strategies, or enhancing user experiences...

Oct 23, 2023
Modern Recommender Systems - Part 1: Introduction
How machine learning methods simplify item discovery and search.
Apr 17, 2023
