Oct 15, 2024
Introducing beeFormer: A Framework for Training Foundational Models for Recommender Systems
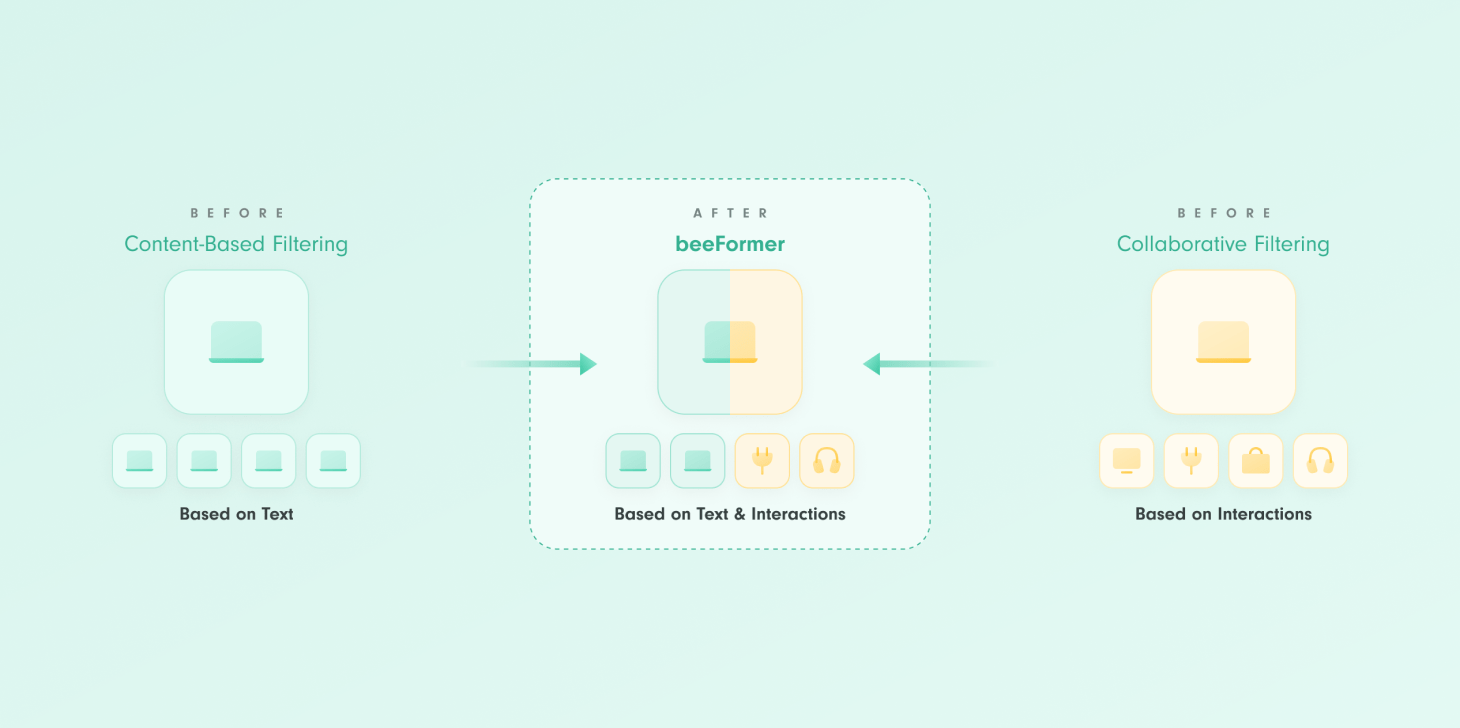
In the fast-evolving world of recommender systems, understanding both how users interact with content and the actual content itself is crucial. Many existing recommender systems struggle to balance these two aspects, especially when there is little interaction data available—commonly known as the "cold-start problem." This issue occurs when new items are introduced, and the system has no past interaction data to rely on for recommendations.
beeFormer is an innovative approach designed to solve this challenge by connecting two types of information: what the items are about (semantic similarity) and how users have interacted with them in the past (interaction similarity). By combining these perspectives, beeFormer makes more accurate recommendations, even in situations where data is limited. Let's take a closer look at how beeFormer works and why it has the potential to transform content recommendations.
The Problem: Semantic vs. Interaction Similarity
Traditional recommender systems rely heavily on collaborative filtering (CF) approaches, which use past user interactions (ratings, clicks, views, etc.) to predict future preferences. However, CF methods falter when there is no historical data to draw from—situations like the “cold-start problem” (new users or items) or zero-shot recommendations (where a system must generalize to unseen content without training on interaction data).
To address these challenges, many systems turn to content-based filtering (CBF), which uses side information like text descriptions or user reviews. While this helps with semantic similarity—how similar two items are in terms of meaning—it often misses how users actually engage with the items. Users don’t always choose items that are semantically similar but rather those that fit their immediate needs or preferences, creating a gap between what a system thinks is relevant and what is actually interacted with.
The beeFormer Solution: Merging Two Worlds
With beeFormer, you are able to recommend not only well established items but also fresh items that do not have any interactions yet. Moreover, beeFormer recommends not only items having semantically similar attributes, but also those that might have high interaction similarity. This significantly improves user experience and lets users discover fresh, diverse and relevant content. This is actually the most important capability of modern recommenders.
Similarly to regular sentence transformer based content based filtering methods, beeFormer turns item text descriptions and attributes into a neural item embedding. This embedding, however, is special because it reflects the knowledge of how items are interacted with together.
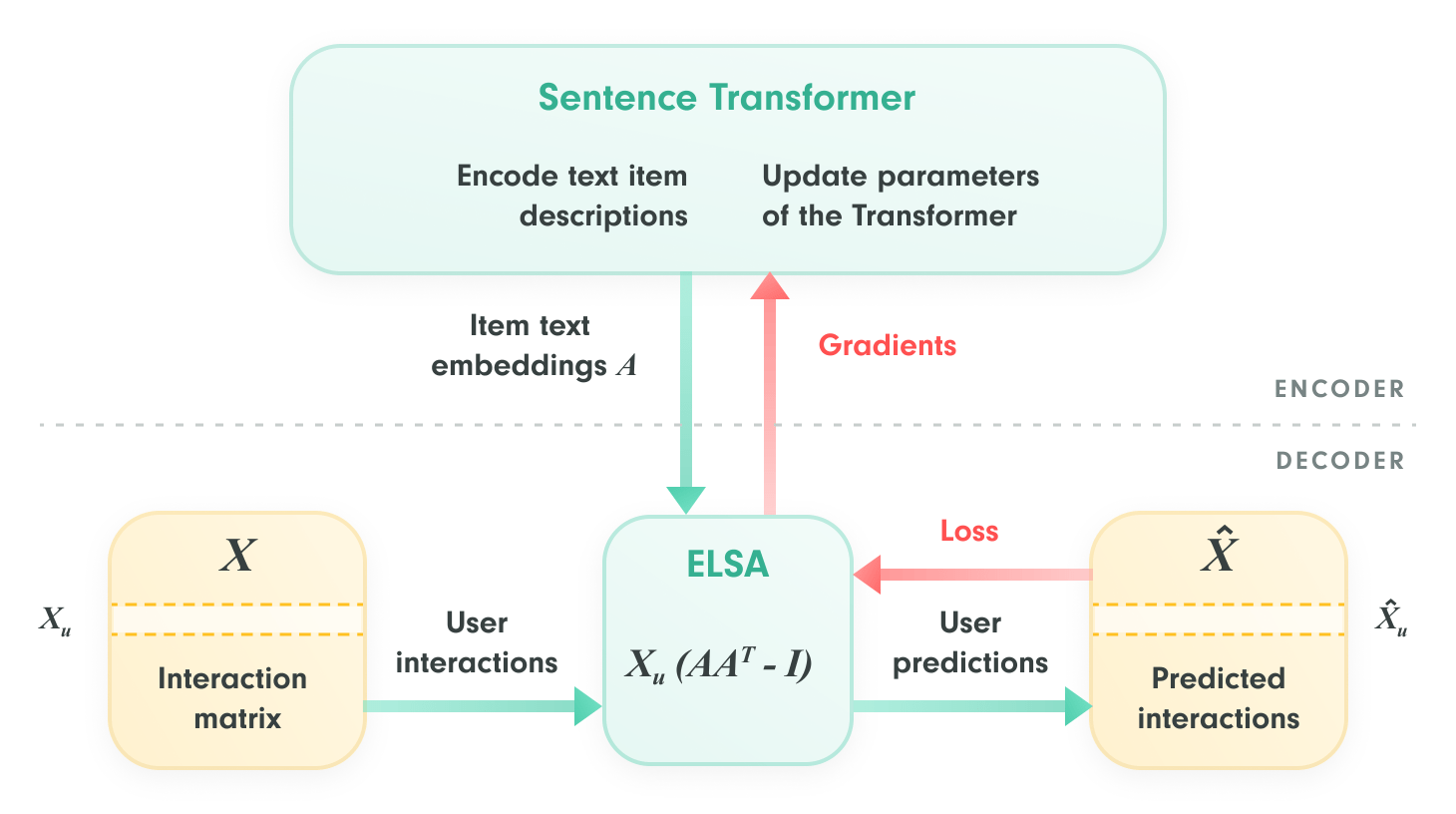
beeFormer integrates the strengths of CF and CBF by training a sentence Transformer model using interaction data, effectively combining semantic knowledge with real-world user behavior represented by interaction data.
What makes this approach unique is its ability to transfer knowledge to unseen items, possibly across domains, allowing it to perform well in cold-start and zero-shot scenarios. For example, beeFormer can transfer insights from movie recommendation datasets to book recommendations, a feat that many current recommender systems cannot efficiently accomplish.
The key lies in how beeFormer optimizes the Transformer’s understanding of item representations. Instead of merely predicting similarities between items based on their descriptions, beeFormer uses interaction data to fine-tune these representations, capturing behavioral patterns specific to how users interact with items.
In a typical beeFormer training workflow:
- Text Encoding with Sentence Transformer: Item descriptions or other side information are encoded into vector representations, providing the semantic basis for recommendations.
- Interaction Data Knowledge Transfer with ELSA: beeFormer uses ELSA, a scalable linear shallow autoencoder, to refine these vectors based on real user interactions. This step injects the behavioral knowledge often missed by semantic-only approaches, allowing the model to better understand actual user preferences at scale.
- Optimization with Efficient Gradient Techniques: To handle large datasets, beeFormer employs techniques like gradient checkpointing and gradient accumulation, enabling the model to scale to massive item catalogs without overwhelming memory resources.
Experimental Results
To verify behavior of beeFormer, we have trained a sentence transformer on the Amazon electronic dataset.
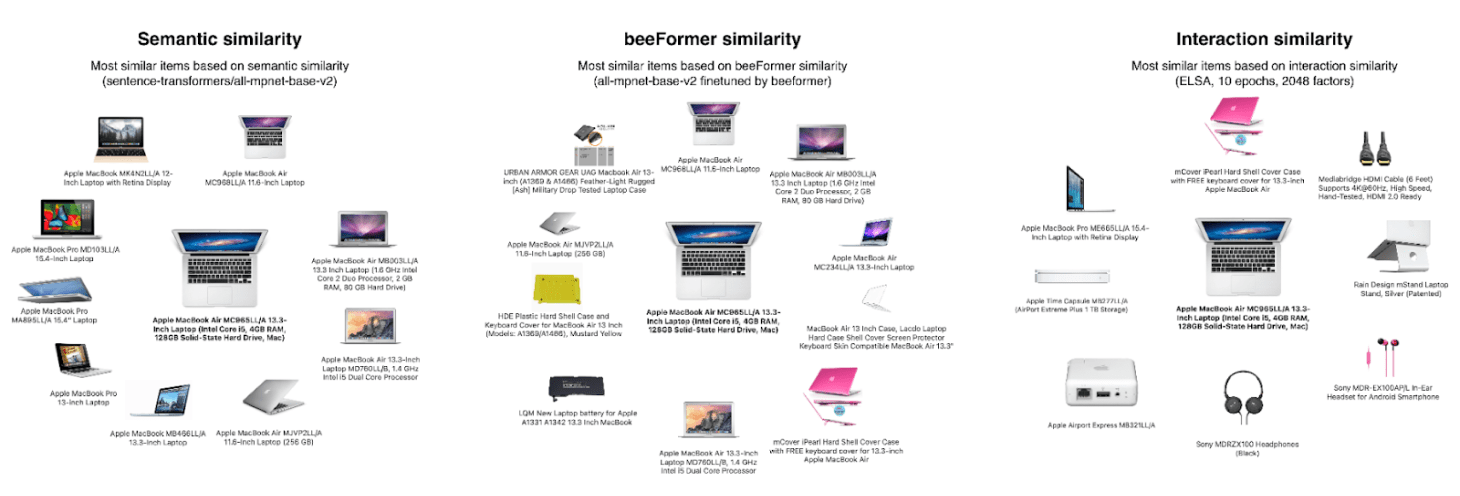
On the left, you can see most similar products to Apple macbook (pure content based similarity). On the right, you can see most similar products based on ELSA collaborative filtering. In the middle, most similar items are based on beeFormer training. Text based semantic similarity is clearly combined with interaction similarity. Note that interactions are not used at all during inference of the model making it applicable to pure cold start scenarios.
We experimented with beeFormer in three key scenarios: Time-Split, Zero-Shot, and Cold-Start. Here’s an explanation of each, along with interpretation of results. In all scenarios, we measured how well models make recommendations using R@20, R@50 and N@100:
- R@20 means the percentage of correct recommendations within the top 20 results.
- R@50 measures this for the top 50 results.
- N@100 indicates a normalized score that takes into account the rank of the recommendation, with a focus on the top 100 results.
To increase the reproducibilty of our experiments we generated item-descriptions by Meta-Llama-3.1-8B-Instruct model. LLAMA 3.1 license allows the use of generated output to train new language models. We add the prefix "Llama" to the names of our models to comply with license terms. Using Llama to generate the item descriptions allows us to publish them. More details about the item description generation are available on our GitHub page.
Time-Split Scenario
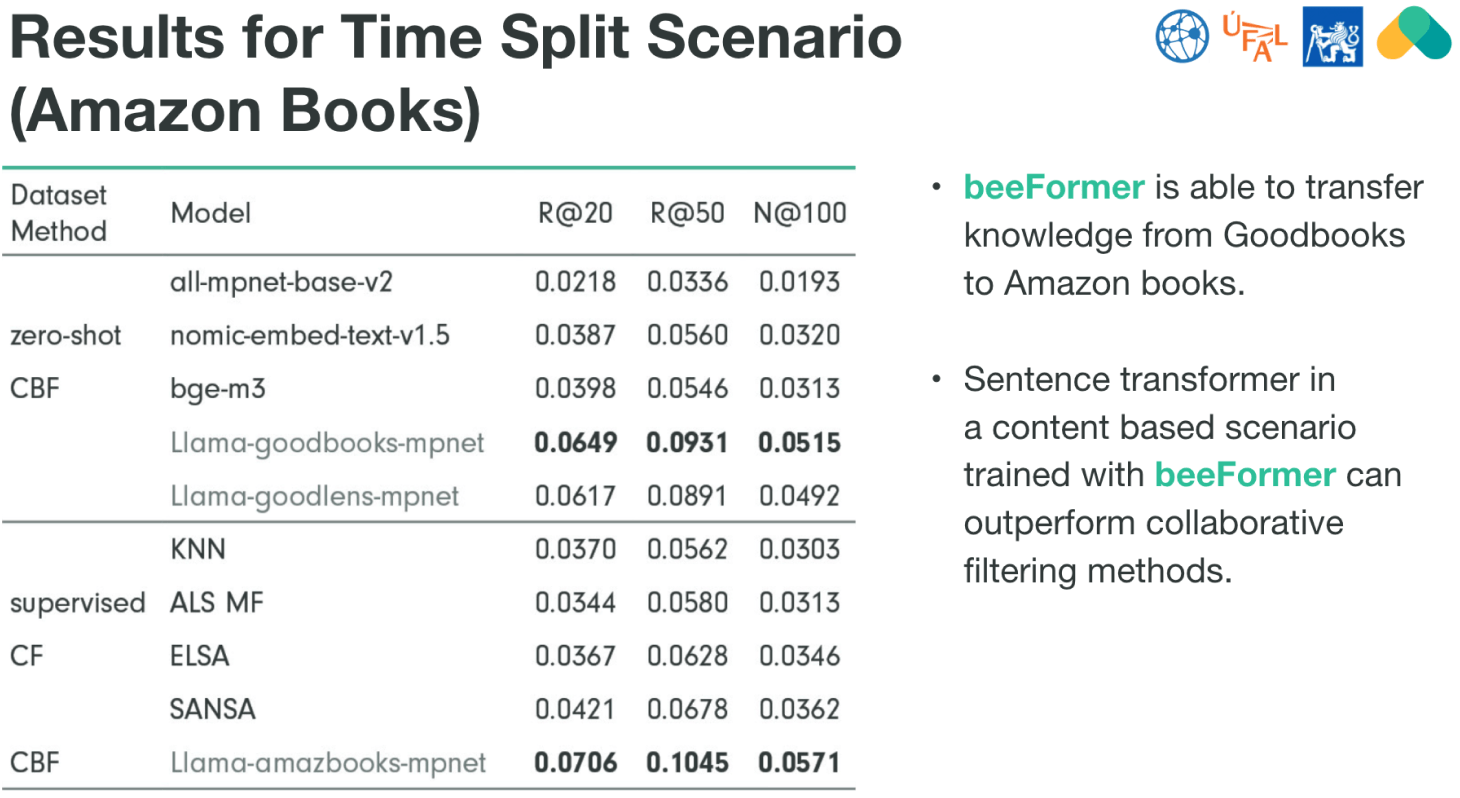
In this scenario, the model is trained on older interactions and tested on newer ones. It mimics a real-world situation where recommendations need to be made based on historical data for new events or items that appear over time. In the Time-Split setup, both traditional collaborative filtering (CF) models and beeFormer-trained models were compared, with the latter showing superior results.The Amazon Books dataset was sorted by timestamp, and the last 20% of interactions were used as the test set, with the remaining 80% used for training and validation. This way, the model must make recommendations for new books based on older user interactions.
Key Observations
- semantic similarity CBF models like nomic-embed-text try to make recommendations without being trained specifically on the dataset. Their performance is lower (e.g., R@20 = 0.0387).
- Collaborative Filtering (CF) models like KNN and ELSA recommend books based on user interactions. Their scores are generally moderate, like KNN's R@20 of 0.0370.
- beeFormer: The standout result here shows that beeFormer, which combines text and user interaction data, is able to transfer knowledge from other datasets (like Goodbooks) and perform well on Amazon books. For example, Llama-amazbooks-mpnet achieves R@20 of 0.0706, the highest score in this comparison.
Zero-Shot Scenario
Zero-shot recommendation refers to the model’s ability to make recommendations for items it has never seen before. This scenario measures how well the model can transfer knowledge from one dataset to another without needing additional training on the new dataset. The model was tested in a way where it was trained on one dataset and tested on another. The model had no prior exposure to the test dataset and needed to transfer its learned knowledge from the training dataset(s) to the test dataset. Various sentence transformer models were tested on two datasets, Goodbooks (GB10K) and MovieLens (ML20M).
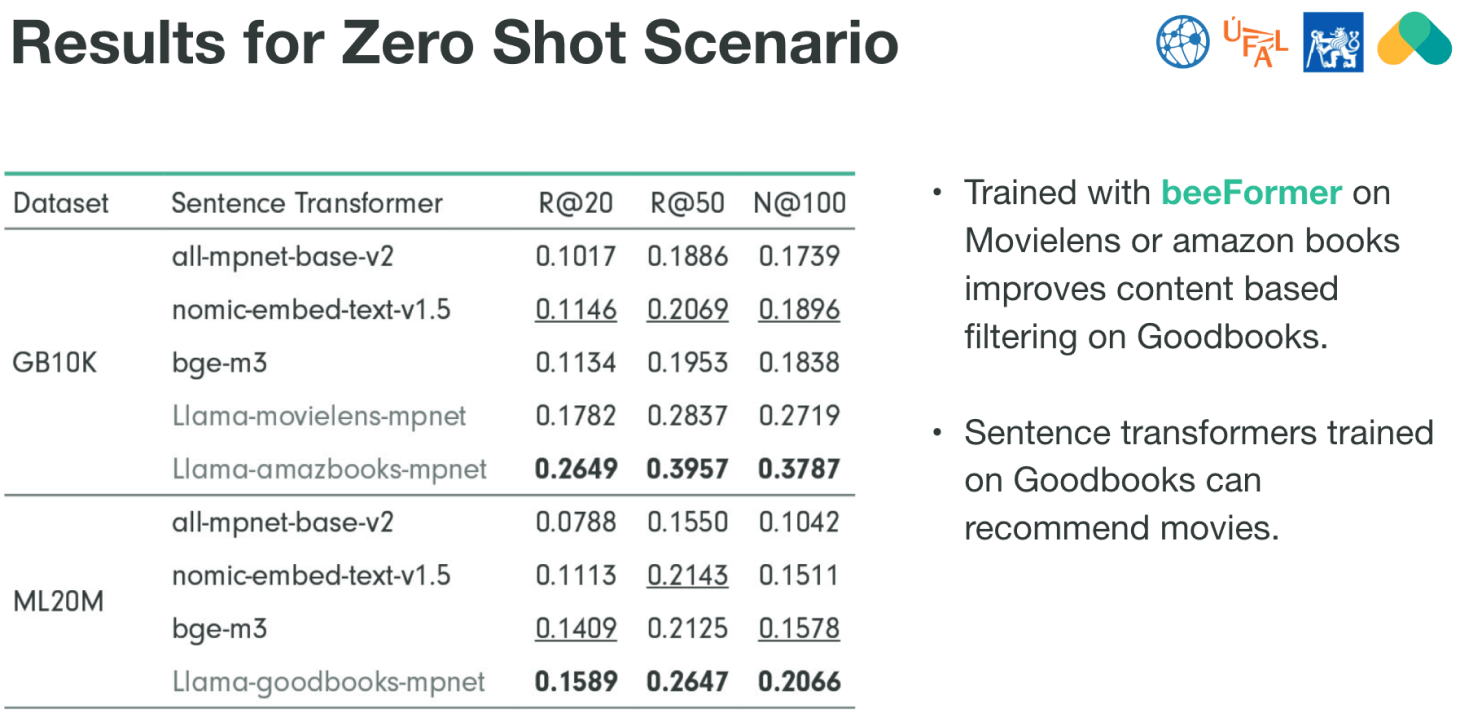
Key Observations
- Goodbooks (GB10K) Results:
- The model Llama-amazbooks-mpnet trained on Amazon Books data performs best, with high scores across all metrics (R@20 = 0.2649, R@50 = 0.3957, N@100 = 0.3787).
- This result shows that beeFormer, which trained on a different dataset (Amazon Books), successfully transfers its knowledge to recommend items from the Goodbooks dataset. This transfer learning improves content-based filtering on Goodbooks compared to other models.
- MovieLens (ML20M) Results:
- Llama-goodbooks-mpnet, a model trained on Goodbooks data, performs best on MovieLens (R@20 = 0.1589, R@50 = 0.2647, N@100 = 0.2066), indicating that a model trained on book data can still recommend movies, showing its versatility and transferability.
Models trained with beeFormer on different datasets (books) can make effective recommendations in entirely different domains (movies), proving the effectiveness of beeFormer in zero-shot scenarios. This capability is critical in real-world systems where new datasets are constantly added, and training from scratch may not be feasible.
The key takeaway is that beeFormer facilitates knowledge transfer across domains, allowing models trained on one type of content (books) to successfully recommend items in another (movies), achieving strong performance without requiring specific training on the target dataset.
Cold-Start Scenario
The cold-start problem occurs when a system has to recommend items with little to no interaction data, such as newly added items or users. In this case, the model has to rely heavily on side information, such as item descriptions. The experiment involved using side information (text descriptions of items) to generalize recommendations to new, unseen items. For benchmarking, Heater (a model that maps interaction data to side information) was used, and the models trained with beeFormer demonstrated superior performance by making use of both interaction and content data.
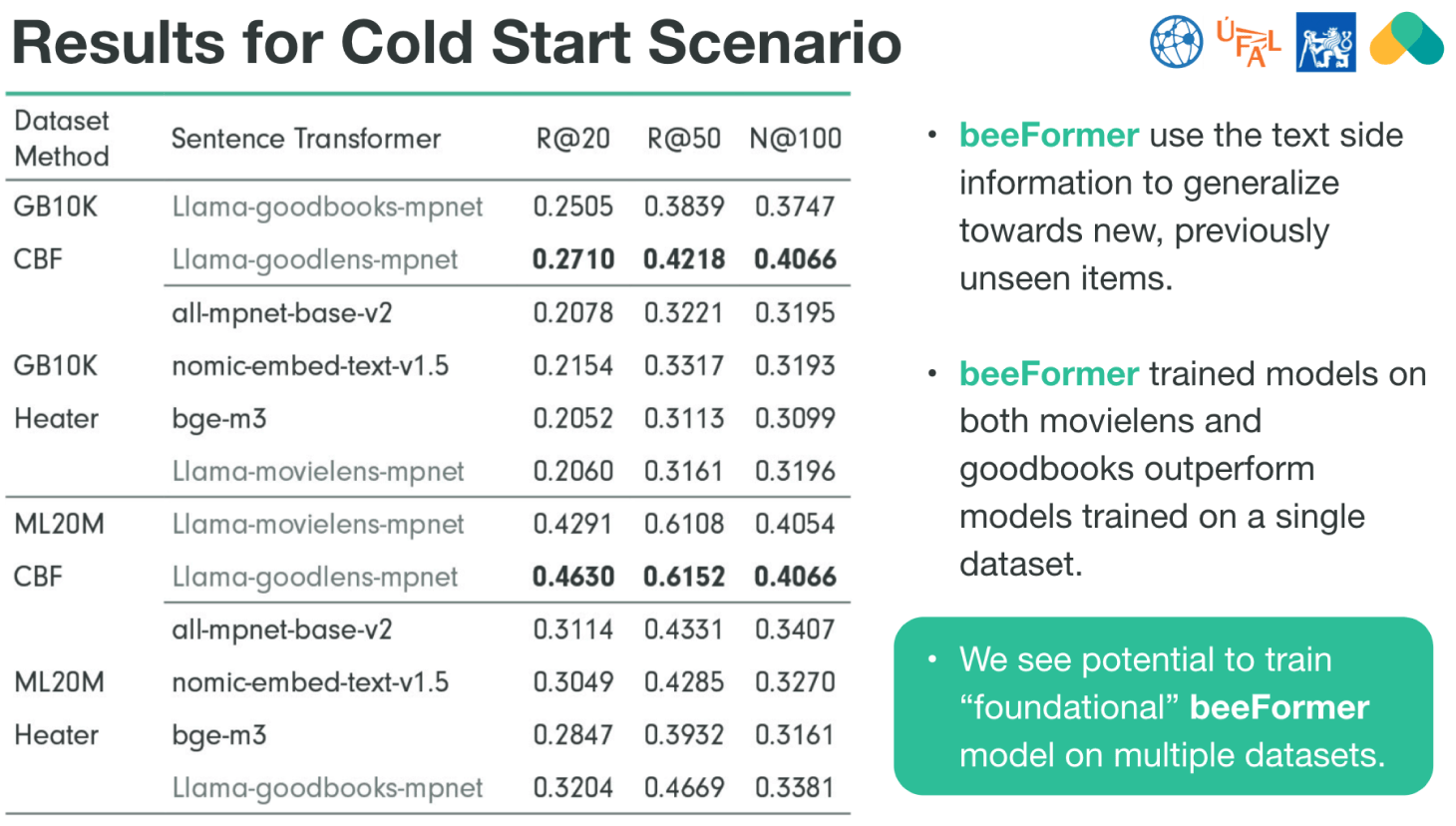
Key Observations
- Goodbooks (GB10K) Results:
- The Llama-goodlens-mpnet trained with beeFormer model performs best in this scenario for GB10K, achieving high recall (R@20 = 0.2710, R@50 = 0.4218, N@100 = 0.4066).
- This model combines knowledge from books and movies, this ability to accumulate knowledge from multiple domains marks an important step towards general, multi-domain recommender systems.
- MovieLens (ML20M) Results:
- The Llama-goodlens-mpnet model again leads the performance in the MovieLens dataset with an outstanding R@20 of 0.4630 and R@50 of 0.6152, indicating it is highly effective in recommending unseen items.
- This demonstrates the model's robustness across domains.
In cold-start scenarios, models rely heavily on side information (such as item descriptions) to generalize and make recommendations for unseen items. The results highlight that beeFormer models, trained on multiple datasets (MovieLens and Goodbooks), outperform models trained on just a single dataset. This emphasizes the model’s ability to leverage knowledge from multiple sources and handle new items more effectively.
Potential for Foundational Models: The conclusion suggests that there is potential to build a "foundational" beeFormer model trained on multiple datasets, making it more versatile and applicable across different domains, helping with cold-start issues across a broad range of applications.
In summary, beeFormer models, particularly Llama-goodlens-mpnet, excel in cold-start scenarios by leveraging text data and performing well across both book and movie datasets. This makes them ideal for situations where new items or users are frequently introduced.
Conclusion: A Bee in Every System?
In conclusion, beeFormer demonstrates remarkable versatility and effectiveness in tackling some of the most challenging scenarios in recommendation systems, such as zero-shot and cold-start. By leveraging the power of text-based side information and combining it with interaction data, beeFormer models outperform traditional methods and other state-of-the-art transformers. The ability to transfer knowledge across domains, as shown in the zero-shot and time-split scenarios, highlights its potential to generalize and perform well on unseen datasets.
Furthermore, in cold-start situations where new items or users are introduced with limited interaction data, beeFormer excels by utilizing foundational knowledge from multiple datasets, making it a valuable tool for a wide range of industries and applications. The success of models like Llama-goodlens-mpnet across different domains suggests a promising future for building universal, foundational recommender systems. With further development and expansion into multi-modal datasets, beeFormer could become a cornerstone of modern recommendation technology, delivering highly personalized and accurate recommendations, even in the most data-sparse environments.
Ready to explore beeFormer? Dive into its source code and learn more on the official GitHub repository. Or contact Recombee to try beeFormer on your data without the need of training and maintaining your model and integrating it into the recommender pipeline.
This research was performed in collaboration with Czech Technical University in Prague and Charles University in Prague.
Next Articles
Celestial Tiger Entertainment launches new Chinese Movie app, CMGO, with DIAGNAL
With Recombee’s AI-powered recommendation engine working with DIAGNAL Enhance, CMGO serves up personalised experiences for each viewer, driving engagement for the service.
Nov 14, 2024

Video Recommendations Made Easy: Integrating Axinom Mosaic with Recombee
In this webinar we look into building a data-driven video backend geared towards personalized video recommendations, integration with Axinom Mosaic, and how to transform user experiences on streaming platforms.
Sep 09, 2024
Insights: The Next Level of Analytics in Recombee UI
Insights, the analytics section of our Admin UI, offers various predefined and fully customizable reports to track recommended items and how users interact with these recommendations.
May 09, 2024